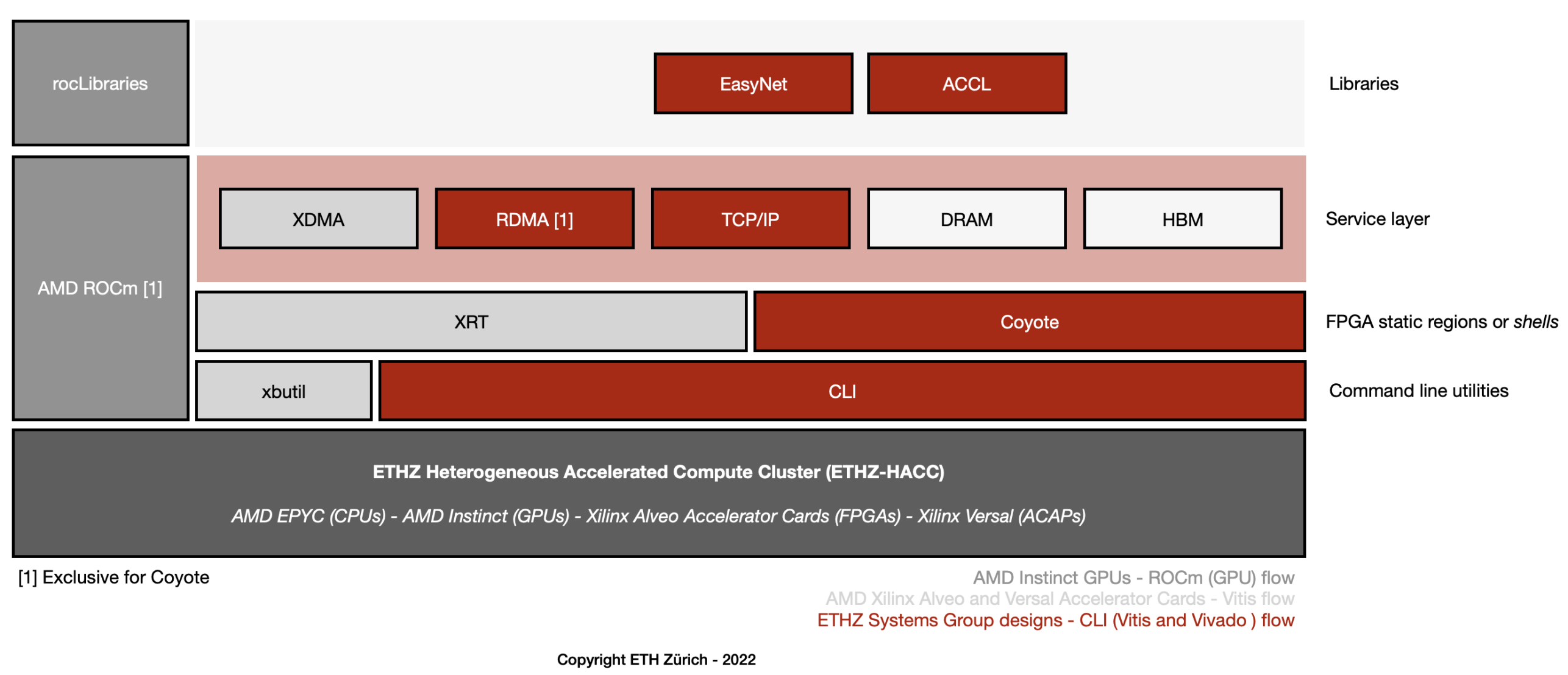
Infrastructure for heterogeneous architectures and hardware acceleration
Research in hardware acceleration is hampered by a lack of an open-source community and open-source resources that can be used to build larger systems. Especially when using FPGAs either for research, prototyping, or systems building, most projects start from scratch, having to build almost the entire stack with every system. We are invested considerable efforts to develop an open-source infrastructure that can be used by us but also by other researchers to explore larger projects and embark on constructing systems that spawn more than a single FPGA or accelerator device. This infrastructure also helps to integrate FPGAs as first-class devices in data centers and the cloud, facilitating their integration with existing systems. Many of these efforts are shared with industry partners, especially with AMD/Xilinx and the Heterogeneous Accelerated Compute Cluster program.
ACCL
Collective operations such as scatter, gather, reduce, etc., are utilized broadly to implement distributed HPC applications and are the target of extensive optimization in all MPI implementations as well as dedicated collective libraries by accelerator vendors (e.g., NCCL and RCCL by NVidia and AMD respectively). In this project, we present ACCL, an open-source FPGA-accelerated collectives library designed to serve applications running on network-attached FPGAs.
See it on external page GitHub
Centaur
external page Owaida, Mohsen, Dr. external page Sidler, David, Dr. external page Kara, Kaan, Dr.
Centaur is a framework for developing applications on a CPU-FPGA shared memory platform, bridging the gap between the application software and accelerators on the FPGA. The main objectives of Centaur are two-folded: at first, to provide software abstractions that hide complexities of FPGA accelerator invocation from software; secondly, to facilitate concurrent access to FPGA accelerators and share them between multiple users.
Centaur exposes an FPGA accelerator as a thread called FThread, which can be created and joined similarly to C++ threads. In addition, Centaur's software abstractions allow combining multiple FThreads dynamically in a pipeline on the FPGA using on-chip FIFOs. Further, Centaur provides data structures to pipeline an FThread with a software function running on the CPU using shared memory. On the FPGA, Centaur implements a thin hardware layer that handles the translation of the FThread abstraction and manages the sharing on-chip resources between multiple users.
See it on external page GitHub
Coyote
Korolija, Dario
Hybrid computing systems, consisting of a CPU server coupled with a Field-Programmable Gate Array (FPGA) for application acceleration, are a typical facility in data centers and clouds today. FPGAs can deliver tremendous performance and energy efficiency improvements for a range of workloads. However, developing and deploying FPGA-based applications remain cumbersome, leading to recent work replicating subsets of the traditional OS execution environment (virtual memory, processes, etc.) on the FPGA. With Coyote, we ask a different question: to what extent do traditional OS abstractions make sense in the context of an FPGA as part of a hybrid system, particularly when taken as a complete package, as they would be in an OS? Coyote is an open-source, portable, configurable “shell” for FPGAs which provides a full suite of OS abstractions, working with the host OS. Coyote supports secure spatial and temporal multiplexing of the FPGA between tenants, virtual memory, communication, and memory management inside a uniform execution environment. The overhead of Coyote is small, and the performance benefit is significant, but more importantly, it allows us to reflect on whether importing OS abstractions wholesale to FPGAs is the best way forward.
See it on external page GitHub
EasyNet
The massive deployment of FPGAs in data centers opens up new opportunities for accelerating distributed applications. However, developing a distributed FPGA application remains difficult for two reasons. First, commonly available development frameworks (e.g., Xilinx Vitis) lack explicit support for networking. Developers are, thus, forced to build their infrastructure to handle the data movement between the host, the FPGA, and the network. Second, distributed applications are even more complex, using low-level interfaces to access the network and process packets. Ideally, one must combine high performance with a simple interface for both point-to-point and collective operations. To overcome these inefficiencies and enable further research in networking and distributed application on FPGAs, we created EasyNet.
EasyNet builds on an open-source 100 Gbps TCP/IP stack (also developed by us; see the project) and provides a set of MPI-like communication primitives—for both point-to-point and collective operations—as a High-Level Synthesis (HLS) library. EasyNet functions saturate the TCP/IP stack without degrading the communication process and are proven to achieve very low latency. With our approach, developers can write hardware kernels in high-level languages with the network abstracted away behind standard interfaces.
See it on external page GitHub
Enzian Coherent Interconnect (ECI) and Directory Controler (EDC)
external page Enzian is deliberately over-engineered computer designed for computer systems software research. Enzian has a big server-class CPU closely coupled to a large FPGA, with ample main memory and network bandwidth on both sides.
ECI
Inter-socket coherence protocols for accelerators are closed with a single coherency model, are non-native with an impedance mismatch with the CPU, and conflate separate concerns such as coherence, caching, and communication. Enzian Coherent Interconnect (ECI) aims to address these issues by providing a deadlock-free interconnect to exchange coherence messages between the CPU and FPGA on Enzian. ECI allows the FPGA to interact with the CPU's native coherence protocol in non-traditional ways, making the CPU believe it is communicating with another. The transport layers of ECI guarantee the delivery of messages through 24 serial lanes spread across two links with a theoretical bandwidth of 30 GiB/s.
EDC
Enzian is a two-node NUMA system with the CPU and FPGA attached to their byte-addressable memories. Enzian is also a symmetric system where each node is responsible for maintaining the coherence of the memory attached to it. The Directory Controller (DC) is an application on the FPGA that enables a shared memory paradigm by allowing coherent access to the byte-addressable memory attached to the FPGA. DC implements the coherence protocol, maintains states of cache lines that belong to the FPGA, and exchanges coherence messages with coherence controllers on the CPU and FPGA through ECI to provide coherent access to any byte-addressable memory attached to it, be it the DDR or block RAM on the FPGA. The DC also allows for a flexible implementation of the coherence protocol depending on the application.
StRoM: Smart Remote Memory
Chiosa, Monica
external page Sidler, David, Dr.
StRoM is a programmable FPGA-based RoCE v2 NIC supporting the offloading of application-level kernels. These kernels can perform memory access operations directly from the NIC, such as traversal of remote data structures and filtering or aggregation over RDMA data streams on both the sending and receiving sides. StRoM bypasses the CPU entirely and extends the semantics of RDMA to enable multi-step data access operations and in-network processing of RDMA streams.
See it on external page GitHub
Systems Characterization
Shi, Runbin, Dr. external page Kara, Kaan, Dr. external page Wang, Zeke, Prof. Dr.
FPGAs are increasingly being used in data centers and the cloud due to their potential to accelerate specific workloads. To meet the challenges posed by these new use cases, FPGAs are quickly evolving in terms of their capabilities and organization. The utilization of High Bandwidth Memory (HBM) in FPGA devices is one recent example of such a trend. However, the performance characteristics of HBM are still not well specified, especially in the context of FPGAs. In this project, we provide a systematic performance benchmark of HBM and study the potential of FPGAs equipped with HBM from a data analytics perspective.