FPL 2023: Network and Memory Abstractions on FPGAs for Distributed Applications
FPGAs are increasingly being deployed in hybrid computing systems in the data centers in a variety of differenct configurations. Such a rapid cloud development makes FPGAs no longer viewed as a slave PCIe-attached accelerator, but as a first-class compute resource directly connected to the network. This opens up lots of opportunities for in-network processing and distributed computing on FPGAs. To fully harness the potential of FPGAs in data centers, it is crucial to address memory virtualization, networking, and resource sharing aspects. These factors play a pivotal role in accommodating diverse applications running in the cloud. However, the availability of comprehensive open-source infrastructure and resources providing a complete stack of abstraction layers is highly limited. Consequently, insufficient attention has been given to utilizing FPGAs in data center scenarios to tackle larger problems and support large-scale deployments.
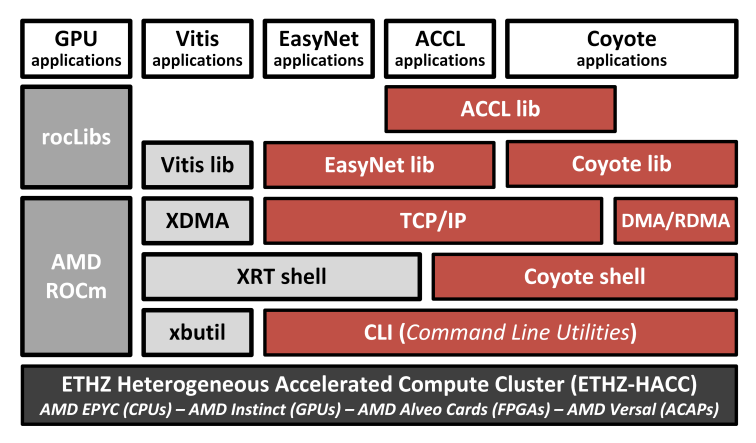
In this tutorial, we will introduce several open source resources that facilitate memory and network abstractions on FPGAs for distributed applications built on FPGA clusters.
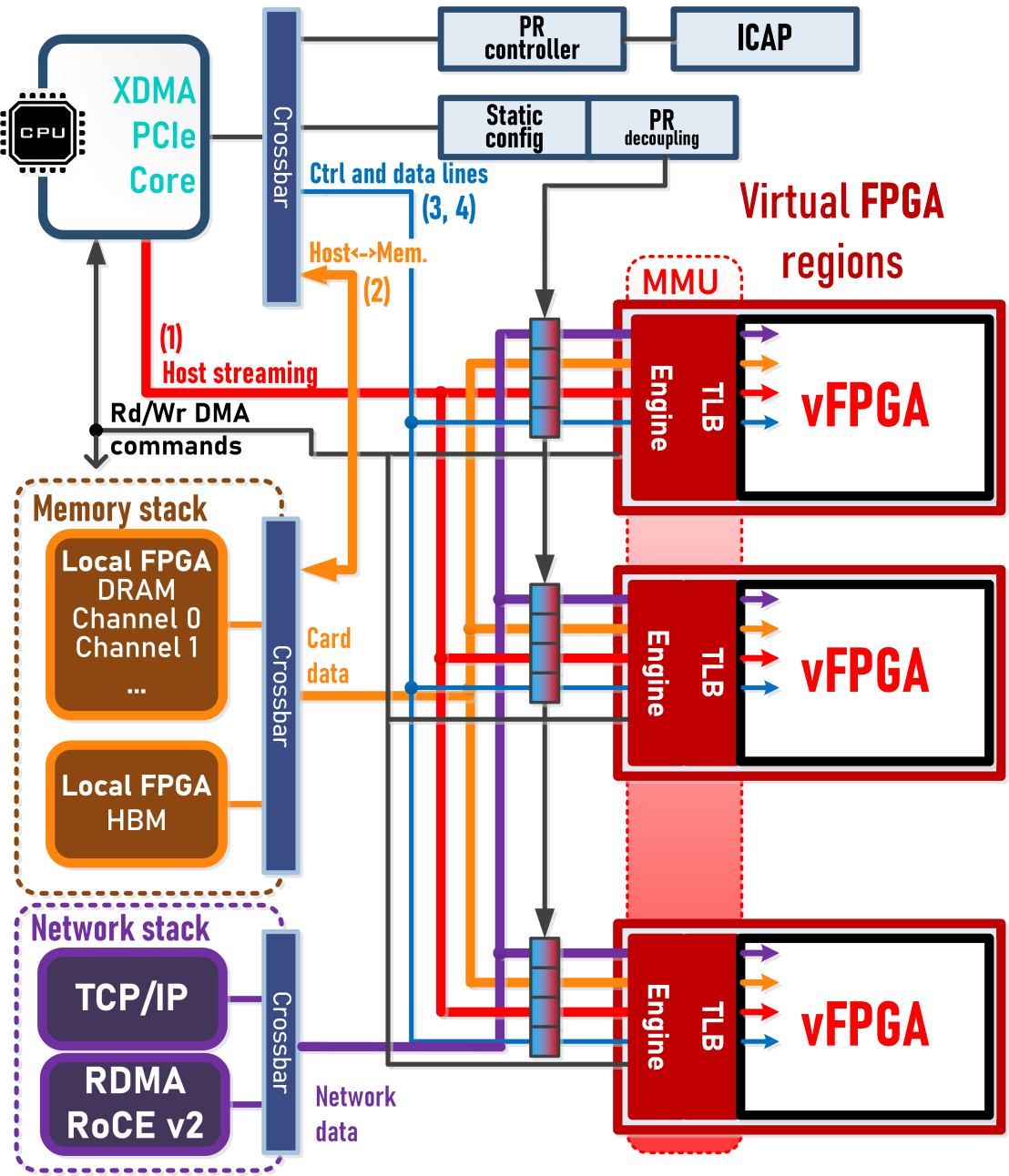
First, we present Coyote, a configurable FPGA shell that provides a
set of traditional OS abstractions which virtualize the available FPGA resources, enabling both spatial and temporal multiplexing of FPGA applications. Coyote also provides a range of memory and networking services, a prerequisite for large-scale distributed applications.
As a second step, we focus on hardware network stacks, e.g., TCP/IP stack with EasyNet and RDMA stack with Coyote, comparable in performance to standard data center infrastructures.
As a third step, we present ACCL, an open-source MPI implementation for FPGAs developed to provide higher level of network abstraction and to simplify the use of networking in machine learning applications. We provide examples of real-world applications that can benefit from executing on network-attached FPGAs in areas like data analytics and machine learning.
In this tutorial, we present not only the design of such resources, but also how to deploy them in the AMD-ETHZ HACC heterogeneous compute cluster, which offers researchers worldwide the opportunity to pursue distributed processing research with network-attached FPGAs.
Location

The tutorial is held on 5th Sep 2023, as part of the conference external page FPL'23. All the slides will be made available shortly before the tutorial.
Schedule
Infrastucture
13:30 – 14:00 Gustavo Alonso, HACC Cluster Introduction
[Download slides (PDF, 1.8 MB)]
14:00 – 15:00 Dario Korolija, Coyote: FPGA OS Abstraction
[Download slides (PDF, 3.6 MB)] [external page github]
15:00 – 15:30 Zhenhao He, EasyNet and ACCL: Network Support for FPGAs
[Download slides (PDF, 1.8 MB)][external page github]
15:30 – 16:00 Coffee Break
Applications
16:00 – 16:30 Dario Korolija, Farview: Disaggregated Memory with In-Network Analytics
[Download slides (PDF, 4.3 MB)]
16:30 – 17:00 Zhenhao He, Distributed Recommendation Inference on FPGA Clusters
[Download slides (PDF, 2.7 MB)]
Demo
17:00 – 17:15 Dario Korolija Coyote Microbenchmark on HACC
17:15 – 17:30 Zhenhao He, ACCL Microbenchmark on HACC

Gustavo Alonso is a professor at the Systems Group of the Department of Computer Science at ETH Zürich. His research interests include data management, distributed systems, cloud computing architecture, and hardware acceleration through reconfigurable computing. Gustavo is a Fellow of the ACM, a Fellow of the IEEE, a distinguished alumnus of the computer science department of UC Santa Barbara, and recently received the ACM EuroSys Lifetime Achievements Award.

Dario Korolija is a doctoral student at the Systems Group of the Department of Computer Science at ETH Zurich working with Prof. Gustavo Alonso. He obtained his MSc degree from EPFL and completed his undergraduate studies at the University of Belgrade in Serbia. Switzerland. He works at the intersection between software and hardware. His main research area is on creating novel abstractions for modern heterogeneous architectures working in the fields of computer architecture, data processing, operating systems and networking (mostly RDMA). He is also interested in recent compiler advancements (MLIR) and their usage for these novel computing systems.

Zhenhao He is a doctoral student at the Systems Group of the Department of Computer Science at ETH Zurich working with Prof. Gustavo Alonso. He obtained his MSc degree from ETH and completed his undergraduate studies at the University of Tongji in China. He works in the intersection of data management, distributed systems and specialized hardware. He also designs hardware accelerators for more efficient data processing in the data center and cloud.