ASPLOS 2025 Tutorial: Open-source infrastructure for FPGAs in the datacenter: from the OS to the network
As Moore’s Law and Dennard Scaling reach their limits, cloud computing is shifting toward heterogeneous hardware for large-scale data processing. Cloud vendors are deploying accelerators, like GPUs, DPUs, and FPGAs, to meet growing computational demands of ML and big data. This tutorial focuses on the deployment of FPGAs in datacenters, since their stream-like computation is perfectly suited for high-performance networking and in-network data processing.
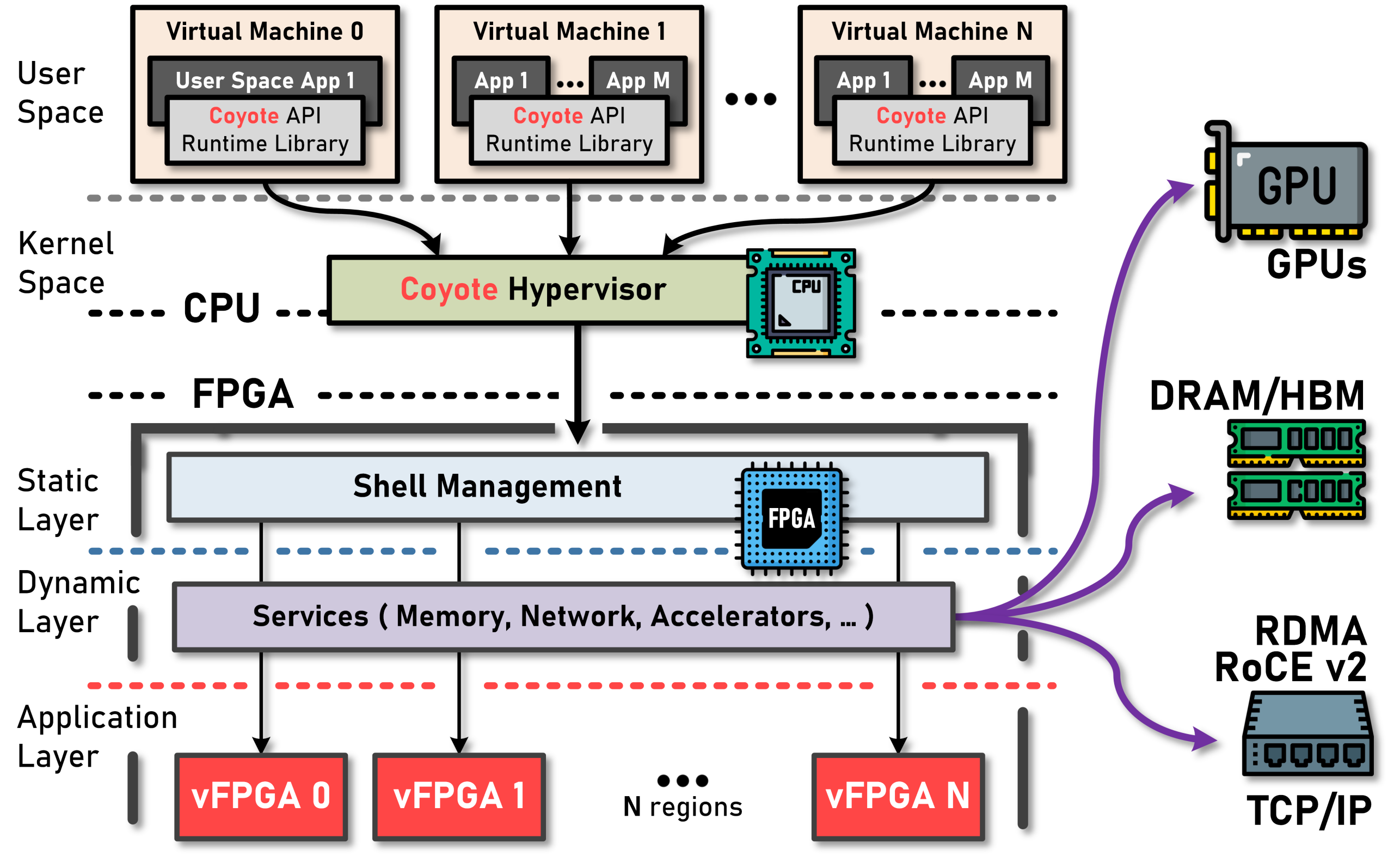
While FPGAs offer great flexibility and performance, practically integrating them in larger systems remains challenging due to the long development cycles and expertise required. To address this, we introduce Coyote v2, an open-source FPGA shell with OS-like abstractions for data processing. Coyote v2 has been re-engineered for flexibility of use as the basis for smartNICs, multi-tenant accelerators, near-memory accelerators, and network-attached processing units.
Participants will explore Coyote v2’s networking stacks, partially reconfigurable vFPGAs for user-defined applications and its internal architecture designed for easy modifications and future research. Of key interest are two additions: (1) a fully RoCEv2-compatible, 100Gbps RDMA stack, with great flexibility for user add-ons, such as line-rate packet inspection and compression, and (2) peer-to-peer data transfer between GPUs and FPGAs, bypassing the host CPU, creating opportunities for research on heterogeneous, high-performance ML systems.

Schedule
- Gustavo Alonso, Introduction (30 min) [Download slides (PDF, 1.9 MB)][Download recording (MP4, 37.4 MB)]
- Benjamin Ramhorst, Coyote v2: An open-source shell for FPGAs (1 hour), including a live demo and examples, overview of Coyote’s internal architecture and potential applications [Download slides (PDF, 3.9 MB)][Download recording (MP4, 85.4 MB)]
- Coffee break (30 min)
- Maximilian Heer, Balboa: An open-source, 100G RDMA stack for FPGAs (45 minutes), including a live demo and examples, focusing on the design, use cases and potential extensions for smartNICs and collective communications [Download slides (PDF, 2.9 MB)][Download recording (MP4, 63.1 MB)]
- Ken O'Brien, GPU-FPGA direct communication (45 minutes), including a live demo and examples, focusing on the design of a direct communication path between the FPGA the GPU with discussion of use cases, applications in AI/ML and possible extensions [Download slides (PDF, 557 KB)][Download recording (MP4, 28.4 MB)]
Materials
GitHub repository for the tutorial: external page link
Coyote documentation: external page link
Relavant literature:
- Coyote v2 primer: "Coyote v2: Towards Open-Source, Reusable Infrastructure and Abstractions for FPGAs", B. Ramhorst et al., LATTE 2025, [external page link]
- Coyote v1: "Do OS abstractions make sense on FPGAs?", D. Korolija et al., OSDI 2020 [external page link]
- Collectives on FPGAs: "ACCL+: an FPGA-Based Collective Engine for Distributed Applications", Z. He et al., OSDI 2024, [external page link]
- RDMA deep packet inspection: "Machine Learning-based Deep Packet Inspection at Line Rate for RDMA on FPGAs", M. Heer et al., EuroMLSys 2025, [external page link]
Speakers

Gustavo Alonso is a professor in the Department of Computer Science of ETH Zurich where he is a member of the Systems Group and the head of the Institute of Computing Platforms. He leads the external page AMD HACC (Heterogeneous Accelerated Compute Cluster) deployment at ETH, with several hundred users worldwide, a research facility that supports exploring data center hardware-software co-design. His research interests include data management, cloud computing architecture, and building systems on modern hardware. Gustavo holds degrees in telecommunication from the Madrid Technical University and a MS and PhD in Computer Science from UC Santa Barbara. Previous to joining ETH, he was a research scientist at IBM Almaden in San Jose, California. Gustavo has received 4 Test-of-Time Awards for his research in databases, software runtimes, middleware, and mobile computing. He is an ACM Fellow, an IEEE Fellow, a Distinguished Alumnus of the Department of Computer Science of UC Santa Barbara, and has received the Lifetime Achievements Award from the European Chapter of ACM SIGOPS (EuroSys).

Benjamin Ramhorst is a second-year doctoral student in the Systems Group at the Department of Computer Science, ETH Zürich. Benjamin obtained his MEng degree from Imperial College London in Electrical and Electronic Engineering, focusing on hardware acceleration for efficient machine learning. During his studies he completed several internships at AMD, CERN and Arm. Benjamin's main research interests are heterogeneous hardware acceleration and distributed computer systems for data processing. More specifically, he is working on data processing through reconfigurable accelerators, both by raising the level of abstractions for infrastructure, through projects such as Coyote and ACCL, as well as custom accelerators for data-intensive tasks, such as neural network inference. Previously, Benjamin published at FPT and OSDI.

Maximilian J. Heer is a second-year doctoral student at the Systems Group of the Department of Computer Science at ETH Zürich. Before joining ETH, he spent a year as a visiting researcher with the Processor Research Team of the RIKEN Center for Computational Science in Kobe, Japan. Maximilian obtained his MSc degree from both The University of Rhode Island (USA) and the Technical University of Darmstadt in Germany, where he also completed his undergraduate studies in Electrical Engineering. Maximilian's main research interest is in network-attached FPGAs for data processing in heterogeneous environments and large-scale cloud computer systems through projects such as Coyote. More specifically, he is working on FPGA-based NICs for high-performance networks, with research questions ranging from support and enhancement of existing transport protocols over the investigation of advanced congestion control and load balancing schemes to the exploration of compute offloading onto such NICs. Maximilian has published at conferences such as FCCM, IPDPSW, QCE and GECCO.

Ken O'Brien is a senior member of technical staff at AMD Research and Advanced Development, in Dublin, Ireland. He has worked in the areas of reduced precision machine learning, bioinformatics, and performance modeling on heterogeneous systems. He is currently researching network acceleration for AI/HPC workloads and systems software for FPGA/GPU disaggregated computing. He is a co-organiser of the H2RC workshop at SC. He holds a PhD in Computer Science from University College Dublin.