Hardware Acceleration for Machine Learning
We are exploring systems for machine learning with a focus on improving performance and energy efficiency on emerging hardware platforms. The configurations we explore range from single accelerator designs, to clusters of homogeneous accelerators, as well as distributed, heterogeneous hardware in the cloud. The topics we are interested in include algorithm design, data formats and representation, hardware-software co-design of algorithms and systems, systems architecture, and overall system design of ML platforms for heterogeneous hardware.
Efficient K-Means Operator for Hybrid Databases
He, Zhenhao external page Sidler, David, Dr. external page István, Zsolt, Prof. external page Wang, Zeke, Prof.
In this project, we explore the challenges and opportunities in designing efficient machine learning operators, particularly K-means, in the context of a hybrid CPU-FPGA database. One challenge of hardware acceleration in the database is the runtime parameterization of the accelerator to avoid frequent reprogramming. The other is the concurrent use of an accelerator to balance memory bandwidth and computation. Thus, we propose a parameterizable runtime design that uses low-precision input in conjunction with a standard K-Means algorithm to improve memory bandwidth utilization on hardware accelerators.
See it on external page GitHub
Efficient processing of ML models in databases
He, Zhenhao external page Sidler, David, Dr. external page István, Zsolt, Prof. external page Wang, Zeke, Prof.
Our ZipML project explores efficient in-database ML training and inference on modern hardware. On the one hand, we build a hybrid CPU-FPGA database that supports on-the-fly machine learning training. On the other hand, we explore low-precision DNN training and inference on FPGAs: we present both single-precision floating-point and low-precision integer (8, 4, 2, and 1 bit) capable FPGA-based trainers and study the trade-offs that affect the end-to-end performance of dense linear model training.
See it on GitHub: external page ColumnML external page MLWeaving external page ZipML-XeonFPGA external page ZipML-PYNQ
Inference of Decision Tree Ensemble on CPU-FPGA Platforms
external page Owaida, Muhsen, Dr.
We explore the design of flexible and scalable FPGA architecture. In addition, we combine CPU and FPGA processing to scale to large tree ensembles with millions of nodes. In this work, we developed an inference system for decision tree ensembles on Intel's Xeon+FPGA platform. The developed system targets XGBoost, one of the most successful boosted trees algorithms in machine learning. In our future steps, we want to explore using low precision for representing either data or tree node's threshold values, which enables the processing of even larger ensembles on the FPGA at higher performance.
Recommendation Systems on Modern Hardware
Jiang, Wenqi Zhu, Yu He, Zhenhao Zhang, Ce, Prof. Dr.
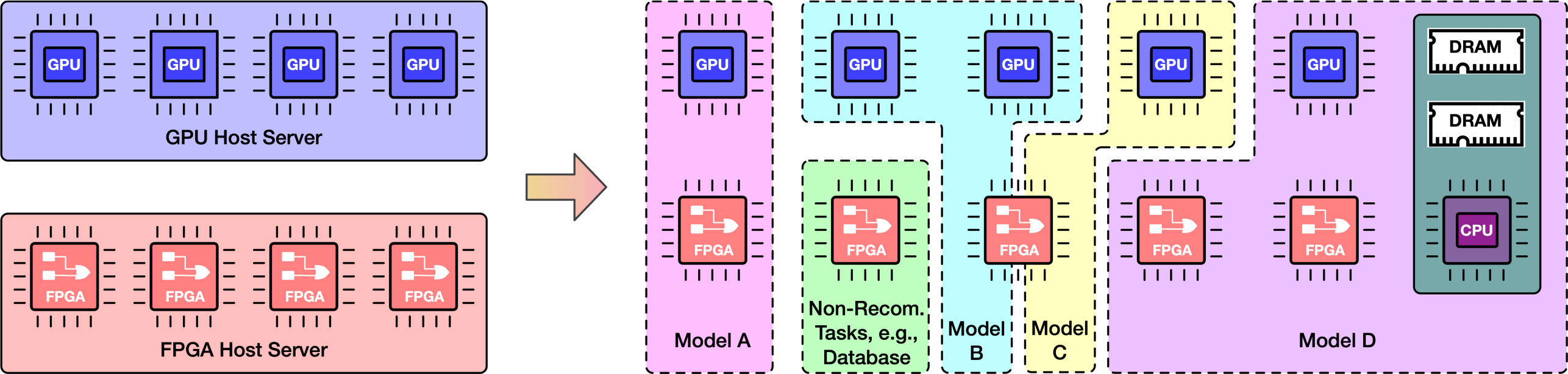
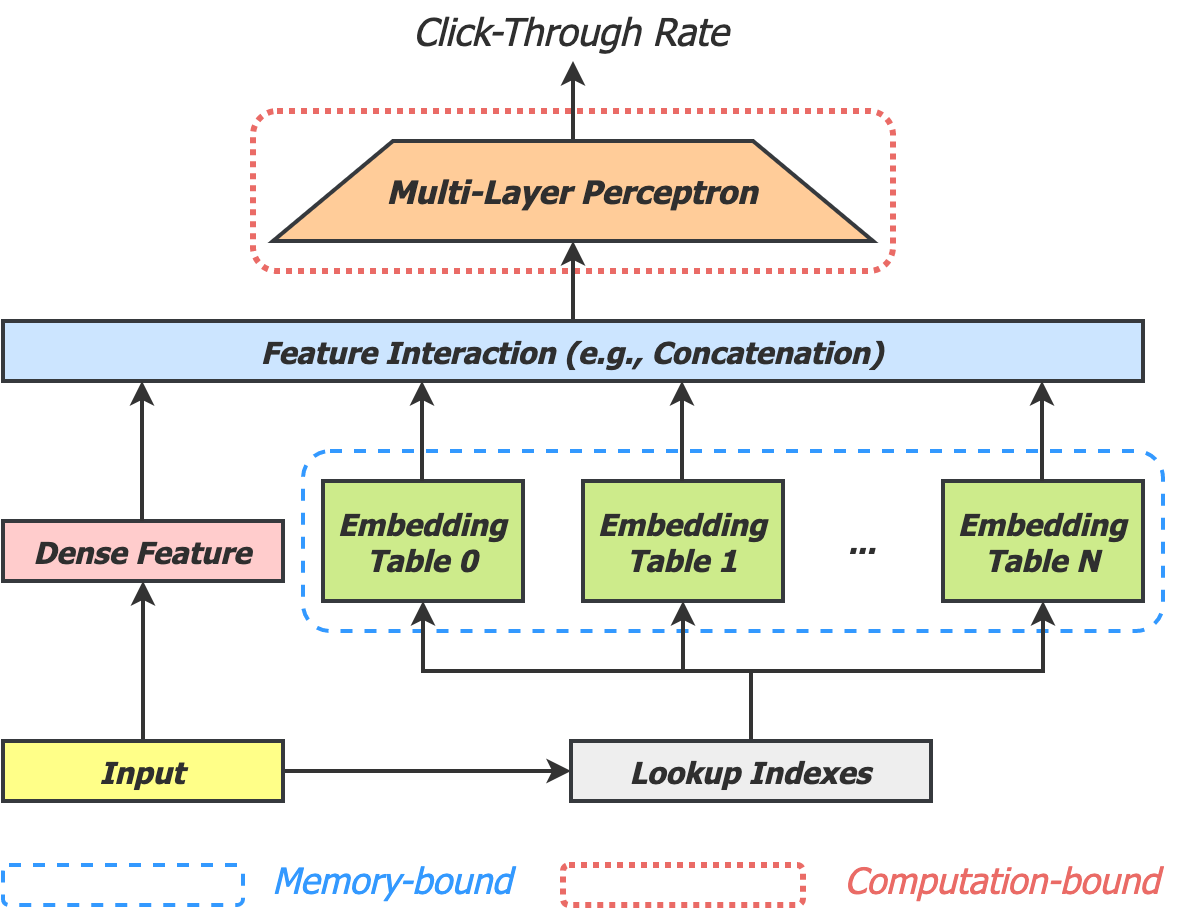
In this work, we explore hardware accelerations of DNN-based personalized recommendation systems on FPGAs and GPUs. Unlike regular DNN inference workloads, which are typically bound by computation, recommendation inference is primarily bound by memory due to the many random accesses needed to look up the embedding tables. To this end, we design MicroRec, a high-performance FPGA inference engine for recommendation systems that tackles the memory bottleneck by both computer architecture and data structure solutions. Once the memory bottleneck is removed, the DNN computation becomes the primary bottleneck due to the limited computation power delivered by FPGAs.
Thus, we further design and implement a high-performance and heterogeneous recommendation inference cluster named FleetRec that takes advantage of the strengths of both FPGAs and GPUs. We are now developing a user-friendly framework for recommendation systems that can automatically deploy models on FPGA clusters.