Modyn

Data-Centric Machine Learning Pipeline Orchestration
The datasets fueling today's production machine learning (ML) models, which typically come from a myriad of sensors or real-time user click streams, are continuously growing. To maintain high accuracy, stale models deployed in the wild need to be retrained in order to incorporate new data, particularly as training data may experience distribution drifts. In practice, models may be retrained as often as every day, while the volume of data that models train on can be as high as petabytes or even exabytes, depending on the application domain.
The cost of continuously training an ML model depends on how frequently we retrain the model and how much data we use to train the model each time. The naive approach of retraining a model from scratch on the entire dataset when new data becomes available is prohibitively expensive and slow. Data selection policies aim to reduce the number of samples that we train on. Complementary to data selection, triggering policies aim to minimize the number of retrainings.
However, finding the right data selection and triggering policies is non-trivial. While ML researchers have explored how to effectively select important samples in a dataset with various strategies, it is not clear what policy to use for real-world datasets that grow and exhibit distribution shifts over time. ML studies in this space often focus on smaller, static datasets, such as CIFAR and MNIST, and do not consider the total pipeline cost. There is a need for a continuous training platform that enables users to explore data selection and (re)training policies.
Growing datasets
Incoming data captures current trends and reveals distribution shifts that can be critical in many application domains. Even in the absence of significant distribution shifts, including additional data over time can enhance model performance as it improves generalization. There are several works in the machine learning community, e.g., for continual learning, data selection, or distribution shift detection, that can be leveraged to orchestrate ML pipelines on growing datasets. However, we are not aware of software systems applying those techniques for end-to-end training of deep neural networks.
Such a platform should efficiently orchestrate continuous training pipelines with configurable triggers and fast access to arbitrary sets of data samples determined by a data selection policy. Model training orchestration and sample-level data fetching should be transparently optimized, and the triggering policies need to be tightly integrated into the data flow, to, e.g., perform drift detection analyses.
The majority of ML training platforms, such as Weights & Biasesor MLFlow, are tailored more towards experiment tracking than continuous retraining. While a few (often commercial) platforms like NeptuneAI, Amazon SageMaker, Continuum, or Tensorflow TFX have partial retraining support, deploying continuous retraining still requires a lot of manual plumbing. The aforementioned platforms view the datasets as a big blob of data instead of indexing individual samples. Especially for modalities commonly used in DNN training (images and text), data-centric decision making on when and what data to train on is, to the best of our knowledge, not supported by any available open-source training platform so far.
The Modyn Platform
Within the EASL group , we are developing Modyn, a data-centric ML pipeline orchestrator to address this gap. It is an end-to-end platform that supports the entire pipeline lifecycle, including sampling-level data selection and management, triggering model retraining, continuously evaluating model quality, and managing model snapshots. The core unit of execution in Modyn is a pipeline. Users declaratively specify the pipeline which allows to decouple the pipeline policy from how it gets executed and lets users focus on model engineering.

The figure above shows Modyn’s components and the basic flow of pipeline execution. Modyn is positioned between the preprocessing of the data and the serving of models. It ingests data from a data source, such as stream processing engines or batch processing frameworks. It outputs a stream of trained models that can then be deployed, using tools like TorchServe or Triton Inference Server. One can think about Modyn as a stream operator that converts a stream of training data into a slower stream of new model versions.
To execute a pipeline, the user submits a pipeline via to the supervisor ⓪, which implements the triggering policy and orchestrates the execution. To allow users to control which individual data samples to access for training, Modyn’s storage component assigns each sample a unique ID and associates metadata with each ID.
The data storage component informs the supervisor about new samples by their key ①. The supervisor checks whether any data point in the incoming batch causes a trigger and forwards potential triggers and the sample keys to the selector ②, which implements the data selection policy. Upon trigger, the supervisor contacts the trainer server to start a training process ③. The trainer server requests the trigger training set (keys and weights to train on) from the selector ④. Then, it loads the actual data from the storage ⑤ and, depending on the configuration, also the previous model from the model storage. The trainer server then runs a training according to the configuration.
The trained model is then stored in the model storage component ⑥. The supervisor can send an evaluation request to the evaluator ⑦, which receives the newly trained model from model storage ⑧, evaluates it and returns the results ⑨. The supervisor can also receive the new model for new triggering decisions ⑩.
Example Pipeline
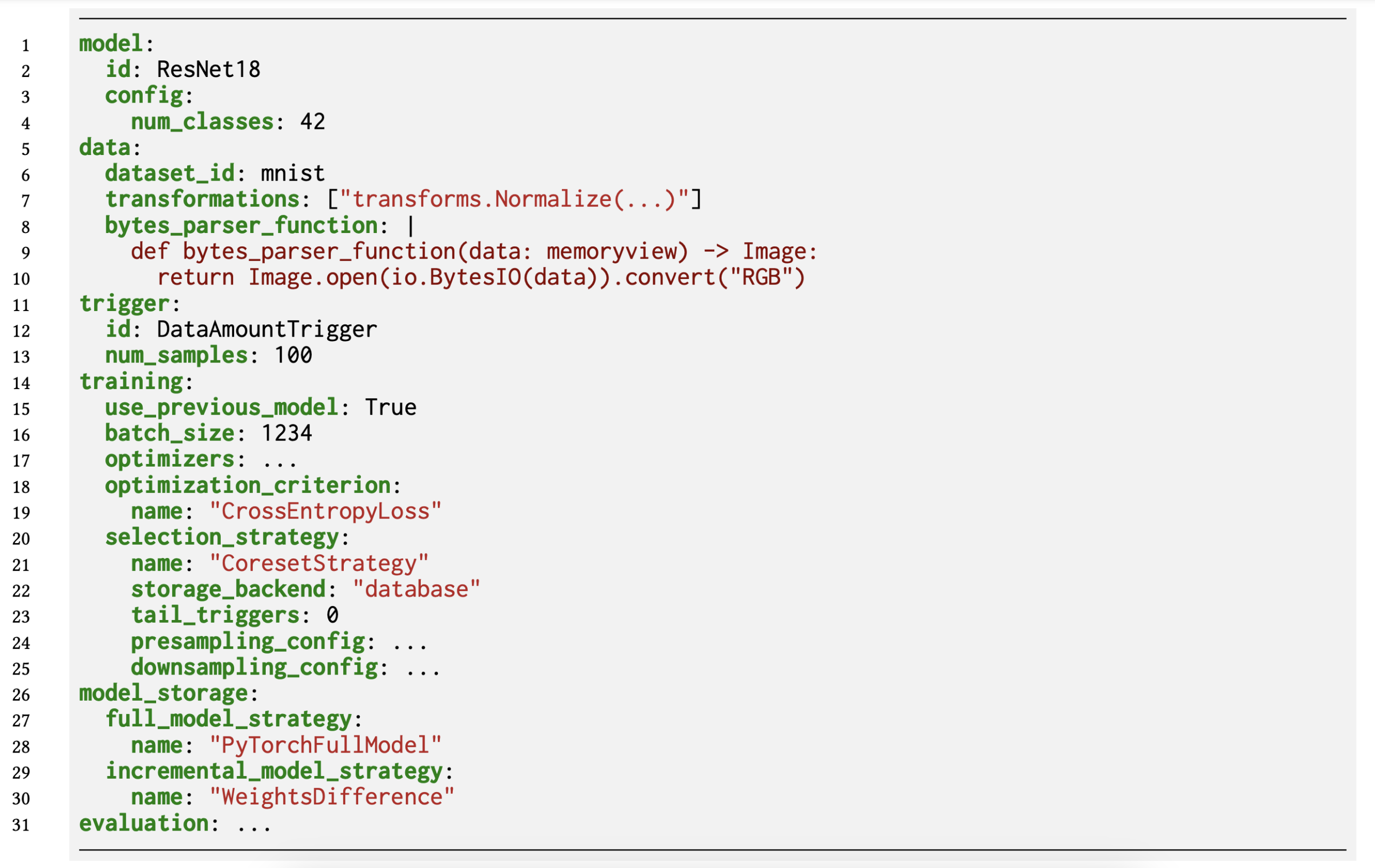
The figure above shows a declaratively-specified pipeline. You can also find external page example pipelines in our Github repository. At minimum, a description comprises the model specification, the training dataset and a corresponding bytes parser function that defines how to convert raw sample bytes to model input, the triggering policy, the data selection policy, training hyperparameters such as the the learning rate and batch size, training configuration such as data processing workers and number of GPUs, and the model storage policy, i.e., a definition how the models are compressed and stored.
A training may involve fine-tuning a model or training a model from scratch with randomly initialized weights; this is a configuration parameter in the triggering policy.
The very first training can run on a randomly initialized or externally provided model.
Case Study: Yearbook dataset
As an example, we showcase the benefits of data-centric orchestration for an ML classification model pipeline, in which the model trains on the yearbook dataset. This dataset consists of yearbook pictures from 1930 to 2013 with binary gender labels.
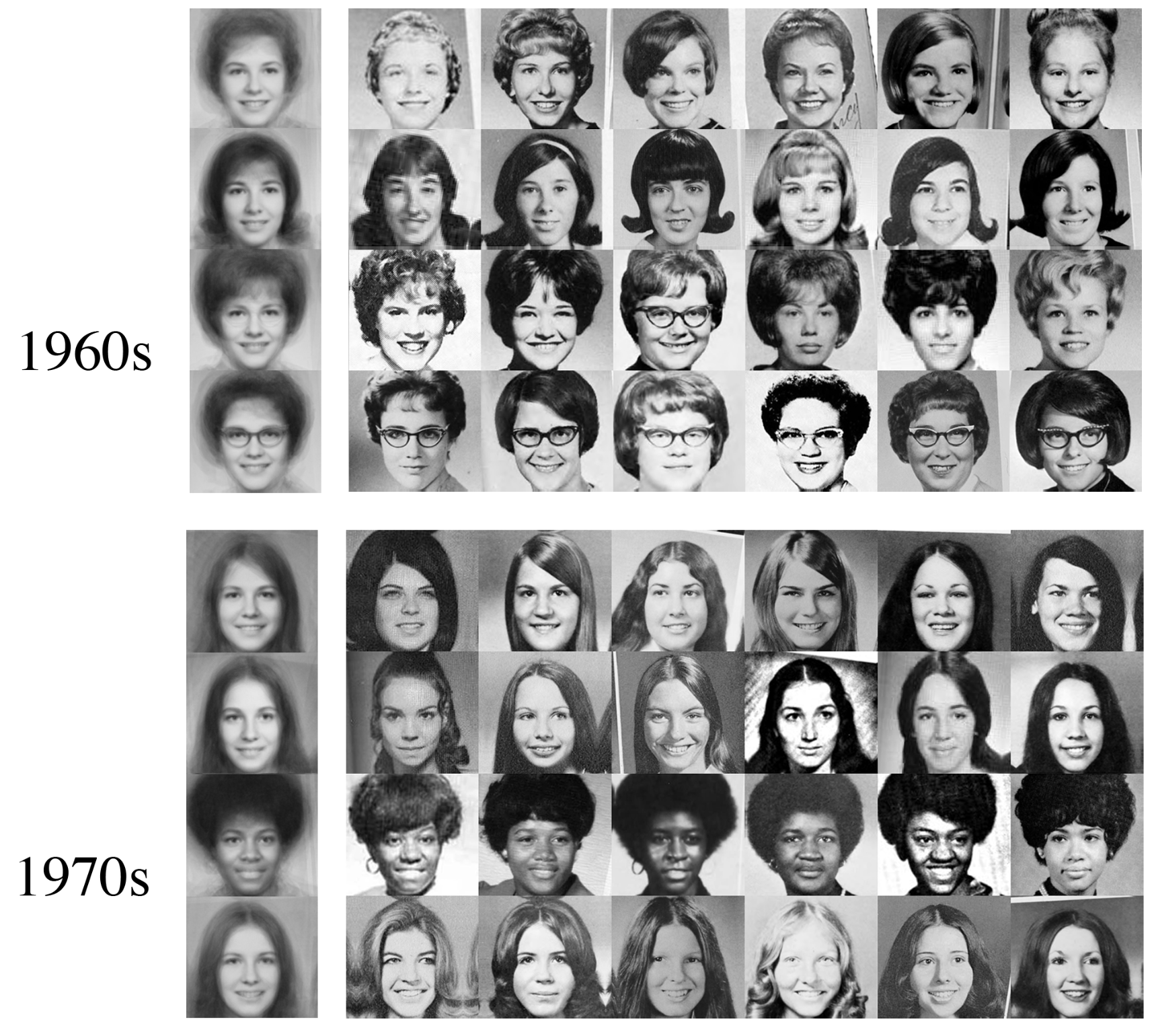
As seen in this example, trends such as hairstyles change over time, such that we can ask ourselves: how does a model trained on old data perform on newer data?
To understand the dataset, we first run an experiment where we train a model with yearly triggers, i.e., the highest triggering resolution possible for this dataset. We always finetune the model from the previous year.

The figure above shows the accuracy matrix when we evaluate each model on validation data for each year, i.e., each cell in this matrix is the accuracy of one model (e.g., 2010) on one year of validation data (e.g., 1965). As expected, the highest accuracies lie on the diagonal of the matrix (models being evaluated on the same distribution they are trained on), and we see that the first models (lower rows) underfit.
We observe two interesting phenomena: First, in the 1970s, there is a drop in accuracy for models trained on data before this period, indicating distribution shift. While a model trained on 1950s data still performs well in the 60s, the models all degrade in performance in the 70s, until they are actually trained on this distribution.
Second, the low accuracies in the upper left area show how models trained on newer data forget the past distribution, i.e., models trained on 2010 data are not good anymore at classifying 1930 pictures.
In the previous experiment, we trigger every year. Can we do it with fewer triggers? We could for example reduce the frequency of the regular time triggers. However, this assumes seasonality in the data and might either still be triggering too frequently or too little. In contrast, drift triggers compare the distributions of the data we trained the model on with the distribution of the incoming data and only fire a trigger when different data comes in.

This figure visualizes the accuracies of a pipeline that triggers when drift occurs instead of yearly. While we leave the technicalities of how to decide when drift occurs to the paper, we can see on the y-axis of the diagram that we reduced the number of triggers (and thereby, trained models) from 84 to 10. Furthermore, the black boxes visualize the “relevant accuracies”, i.e., the accuracies one would see when they actually deployed this pipeline. We call this the currently active model in the paper.
Considering the drift region in the 1970s, shortly before the accuracies of the 1954 model would degrade, the pipeline fires a trigger and thus manages to navigate around the drift area without ever entering a low-accuracy regime. This is in contrast to, e.g., performance triggers that trigger when model performance degrades below a certain threshold. Such triggers are only viable if we have labels (that in practice often come in late), and only allow reacting to already degraded performance, while drift triggers react to changes even before they have an impact on accuracy.
Conclusion
Modyn is our data-centric ML pipeline orchestrator that allows ML researchers to explore data selection and triggering policies by running pipelines end-to-end. If you are curious about ML pipelines, we encourage you to read our external page SIGMOD’25 paper, in which we discuss in more technical detail how different data selection and triggering policies work, and how pipelines with different triggering policies can be fairly compared. Modyn’s source code can be found at external page https://github.com/eth-easl/modyn. If you have any questions on Modyn, please do not hesitate to reach out.
This project is joint work by external page Maximilian Böther, external page Ties Robroek, external page Robin Holzinger, external page Xianzhe Ma, external page Pınar Tözün, and Ana Klimovic.