Dirigent
Dirigent: Lightweight Serverless Orchestration
A serverless orchestration framework by:
Lazar Cvetković, François Costa, Mihajlo Djokic, Michal Friedman, Ana Klimovic
Today’s function-as-a-service (FaaS) infrastructure is built by retrofitting legacy systems. Serverless frameworks typically use a traditional orchestration system like Kubernetes (K8s) as the underlying cluster management framework and implement serverless-specific features such as per-function autoscaling and automatic resource management.
However, we find that building serverless platforms on top of legacy cluster management infrastructure heavily limits performance, since these systems are built to orchestrate clusters with long-lived workloads whose startup time is amortized over long execution time. Serverless workloads consist of fine-grained, short-running functions with high sandbox churn, which requires low latency and high throughput scheduling by the cluster manager.
To evaluate the performance of today’s systems, we set up an experiment in which we measure and break down the end-to-end latency of cold starts, i.e., invocations that have sandbox creation on their critical path. We aim to quantify how efficiently the cluster manager, which is responsible for sandbox creation, can handle sandbox churn. We use the Knative serverless framework on top of the K8s cluster manager, which is a representative serverless framework used in serverless research (e.g., external page vHive) and as a commercial cloud offering (Google Cloud Run for Anthos). The following figure shows the results of our experiment.
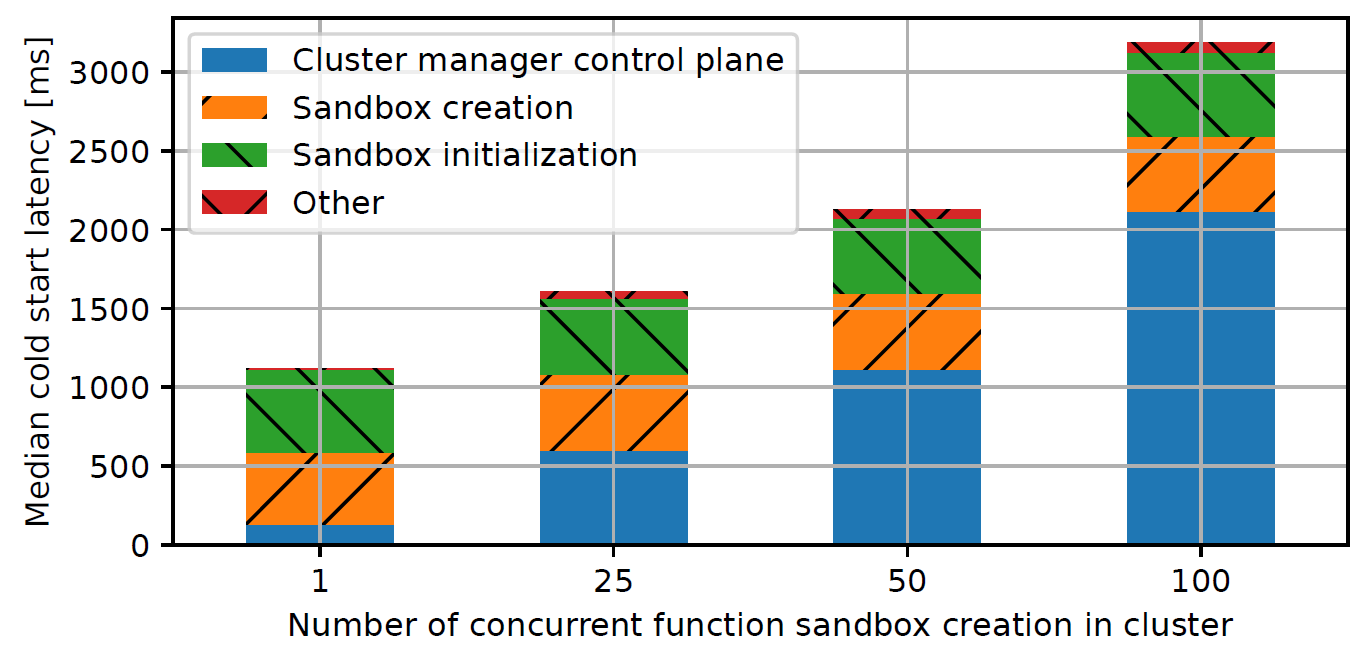
While the worker node latency for creating and initializing a sandbox remains constant as we increase the number of concurrent sandbox creations in the cluster, the centralized cluster manager control plane becomes the bottleneck. The cluster manager control plane is responsible for scheduling each sandbox onto a particular worker node and plugging each newly created sandbox into the cluster so that it can start receiving requests. When the cluster experiences 100 concurrent cold starts, the cluster manager control plane accounts for 65% of end-to-end cold start latency.
Looking beyond Knative, we conduct a similar experiment on AWS Lambda. We observe a similar increase in end-to-end latency when concurrently starting many sandboxes (though unfortunately we have no way to analyze the latency breakdown).
Root cause analysis
To understand the root cause of inefficiencies in FaaS cluster managers that causes the performance degradation we observed on cold starts, we first delve into the architecture of today’s platforms, taking Knative (which runs on top of K8s) as an example.
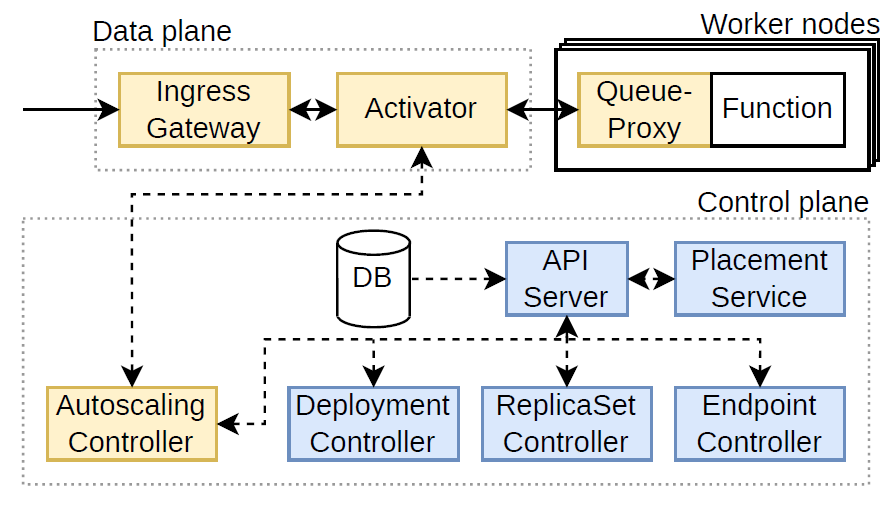
A Knative cluster consists of a data plane, a control plane, and worker nodes. Kubernetes provides tens of control plane abstractions, many of which are hierarchical, such as Deployments, ReplicaSets, and Pods. Deployments consist of a ReplicaSet, which logically encompasses Pods. Together, these abstractions enable declarative function scaling. Each abstraction is associated with a controller that reconciles the actual state to the desired state.
Although serverless computing research has focused on designing scheduling policies, we find that the fundamental bottleneck lies in sandbox scheduling mechanisms. In Knative, when the autoscaling controller decides to add a new sandbox, the decision needs to be propagated to numerous Knative and K8s controllers. However, controllers cannot exchange information directly. Instead, they write
and read state in a strongly consistent cluster state database (etcd) with synchronous read-modify-write sequences. All controller communication via the database goes through the K8s API Server (the control plane front-end), which quickly saturates CPU cycles as it spends most of its time (de)serializing control plane messages. The tree-like cluster state schema is not optimized for efficient serialization operations.
A solution – Orchestrating Serverless Clusters with Dirigent
Having understood the origins of the performance problems in today’s serverless orchestration systems, we derive design principles to solve the current challenges. As we will see, these design principles are fundamentally at odds with the K8s system architecture design. Hence, we build a clean-slate cluster manager catered for serverless, Dirigent. It maintains the same end-user API as today’s serverless platforms, but rethinks which cluster state needs to be stored and persisted under the hood and how it gets updated.
Dirigent’s system architecture is shown below. A Dirigent cluster consists of a control plane component, a data plane component, and worker node processes. The control plane component is replicated, with only one replica active at a time. The data plane is also replicated, with each replica active and operating independently to load-balance requests of different functions.
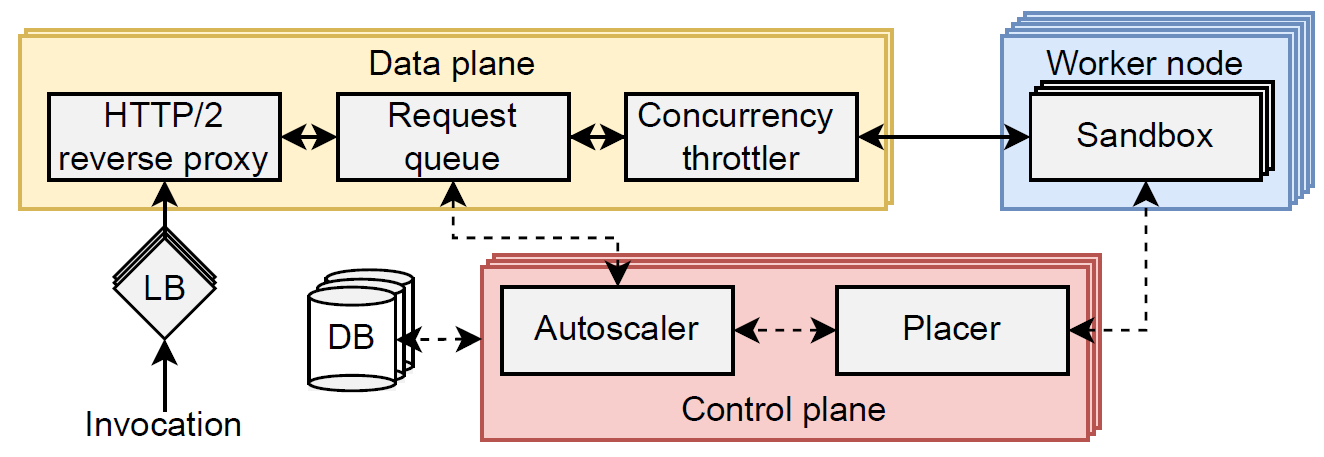
A function invocation arrives in Dirigent through the front-end load balancer (LB) and reverse proxy. If there is a sandbox to handle the invocation (i.e., a warm start), the data plane picks a sandbox that will execute the invocation, ensures the sandbox has an available processing slot, and proxies the request to the worker node. If no sandboxes are available to process a request when it arrives (i.e.,
cold start), the invocation waits in a data plane's request queue until at least one sandbox becomes available. The data plane periodically sends autoscaling metrics to the control plane. The autoscaler in the control plane determines the number of sandboxes needed to serve the current traffic. When a new sandbox needs to be created, the placer chooses and notifies the worker node that should spin up the new sandbox. Once a sandbox is created, the worker daemon issues health probes to ensure the sandbox is booted and ready to handle the traffic. After the sandbox passes a health probe, the worker daemon notifies the control plane, which then broadcasts endpoint updates to data plane components. The data plane dequeues the request and handles it as a warm start. Requests leave the system in the reverse direction and pass through the same data plane to reach the client.
Dirigent differs from K8s-based cluster managers like Knative in three key ways. We apply the following three design principles:
- Simple internal abstractions – The cluster manager abolishes the hierarchical K8s scaling abstractions to vastly simplify the autoscaling critical path, reduce the number of control loops, and optimize communication. Dirigent proposes just 4 abstractions describing functions, sandboxes, data planes, and worker nodes (see the table below). Furthermore, Dirigent chooses to minimize the amount of state associated with each abstraction. Having fewer abstractions implies less state to manage, cheaper serialization, and fewer consistency issues. Dirigent also optimizes the cluster state storage schema
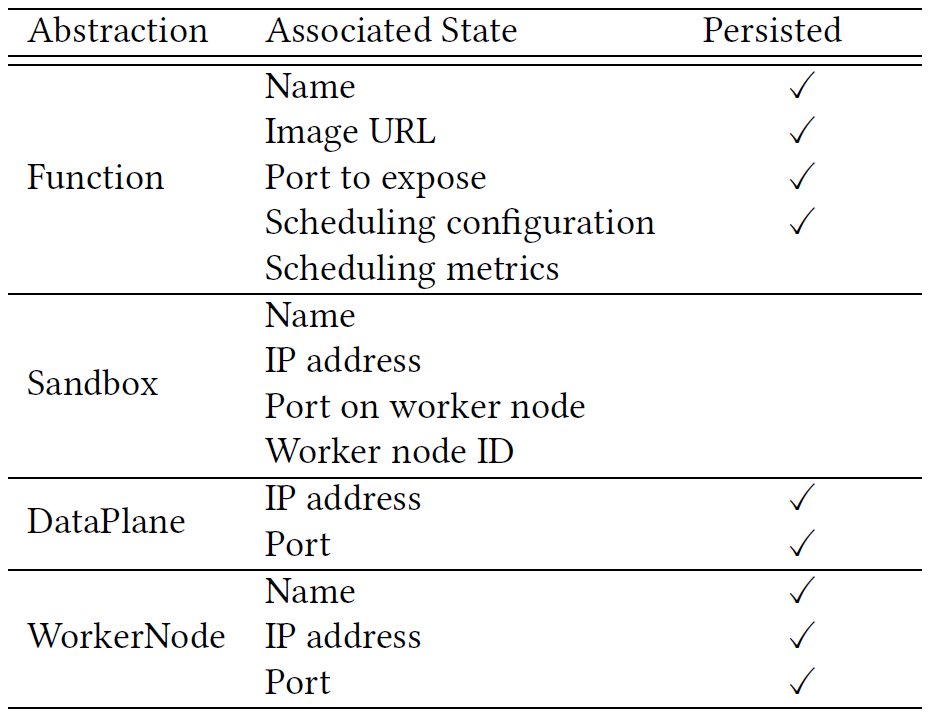
- Persistence-free latency-critical path – Persisting data to a database on the critical path of an invocation is detrimental to performance, i.e., there is a fundamental fault tolerance vs. latency tradeoff in cluster managers. In contrast to K8s, which optimizes the former, Dirigent optimizes for low scheduling latency by persisting minimal state. In particular, Dirigent does not persisting state that can be recovered from other cluster components. For example, if a control plane component fails, the newly elected replica will get information about existing sandboxes from the worker nodes. In multi-component crash scenarios, the scale of all sandboxes will be zero, but since Dirigent quickly schedules new sandboxes, the cluster will quickly converge to the correct state for serving the current traffic demand. The corollary to not persisting each cluster state update to the database is that the cluster may not necessarily recover to the exact same state as before the failure. However, this is not required for serverless platforms, as they hide the exact number and node placement of function sandbox from users.
- Monolithic control and data planes – We chose to centralize functionalities for sandbox management into a monolithic control plane, which inherently allows simpler bookkeeping, fewer leader elections, and eases development. The monolithic data plane allows Dirigent to achieve lower infrastructure-added latency on a per-invocation basis, and to abolish sandbox sidecars, thereby reducing per-sandbox memory usage. However, the control and data plane are not further fused, since we want to allow for independent scaling of each component, for performance and process-level fault tolerance reasons.
Dirigent currently supports containerd and Firecracker sandbox runtimes and implements the same autoscaling, load-balancing, and placement policies that Knative supports. Dirigent exposes numerous performance metrics to the system administrator. Currently, Dirigent provides process-level fault tolerance, i.e., it guarantees that each cluster component will try to restart and reconnect to the cluster. However, on the request-level fault tolerance side, for synchronous requests, Dirigent provides no guarantees, similar to Knative and OpenWhisk baselines. For asynchronous requests, we do provide at-least-once guarantee, through a retry policy.
We are currently adding support for executing function workflows, request-level fault tolerance guarantees, and support for additional sandbox runtimes.
Evaluation
In the following experiments, we show how Dirigent’s performance compares to Knative and OpenWhisk baselines, for microbenchmarks and real workloads. We evaluate Dirigent on a 100-node cluster, where each node is an Intel Xeon E5-2640 v4 @ 2.4 GHz CPU with 10 physical cores and 64 GB of DRAM. For AWS Lambda experiments, we register functions in the us-east-1 region and invoke functions from T3 EC2 instances in the same region.
First, we conduct a cold start microbenchmark. In this experiment, we sweep the sandbox creation rate (i.e., cold starts per secod) and monitor the end-to-end latency.
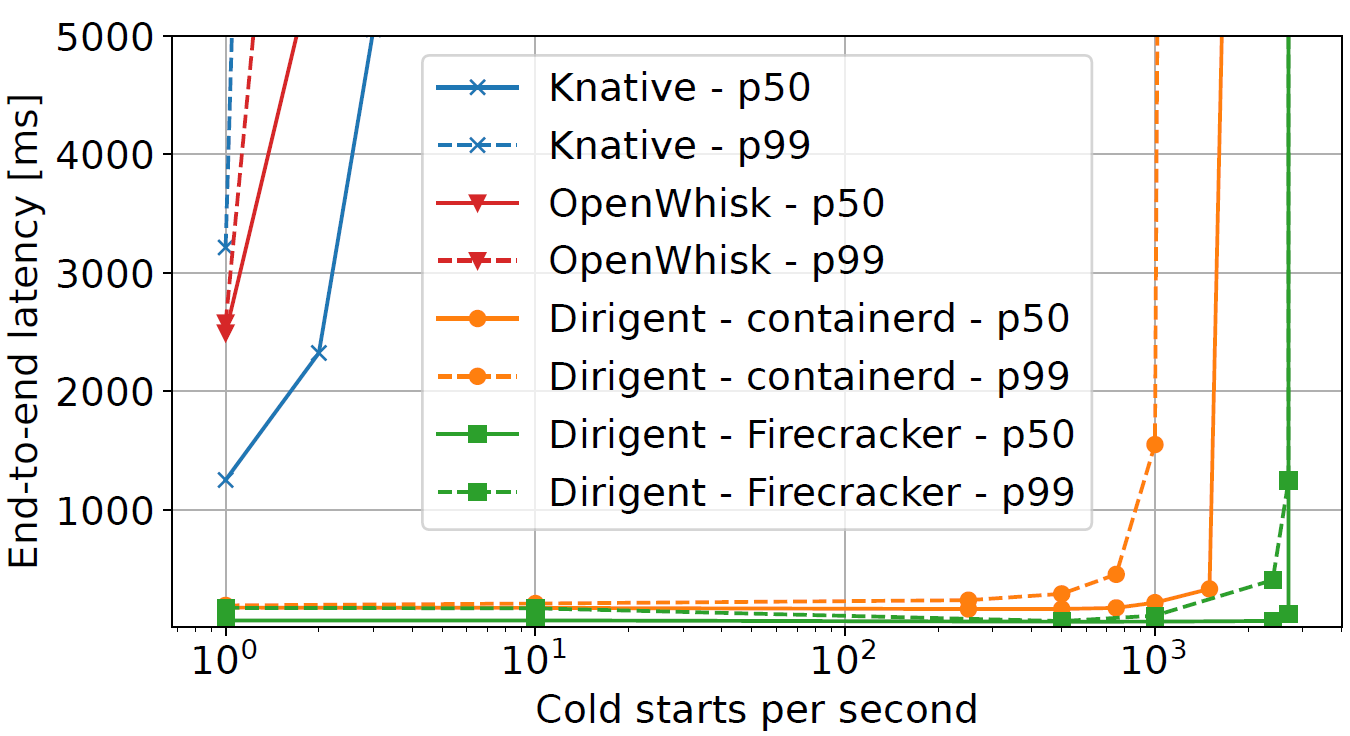
As seen in the figure, K8s-based systems like Knative and OpenWhisk saturate the control plane with just a couple of cold starts per second. On the other hand, Dirigent manages to achieve 1250x higher throughput than K8s-based systems while incurring much lower latency. We also evaluate Dirigent’s scalability and determine its performance for both cold and warm invocations remains unaffected in clusters consisting of up to 2500 nodes.
Finally, we evaluate Dirigent on a sampled Microsoft Azure production serverless workload trace and compared the performance of Dirigent, Knative, and AWS Lambda. Dirigent reduces per-function slowdown at the 99th percentile by 6.9x compared to AWS Lambda, and by over three orders of magnitude compared to Knative.
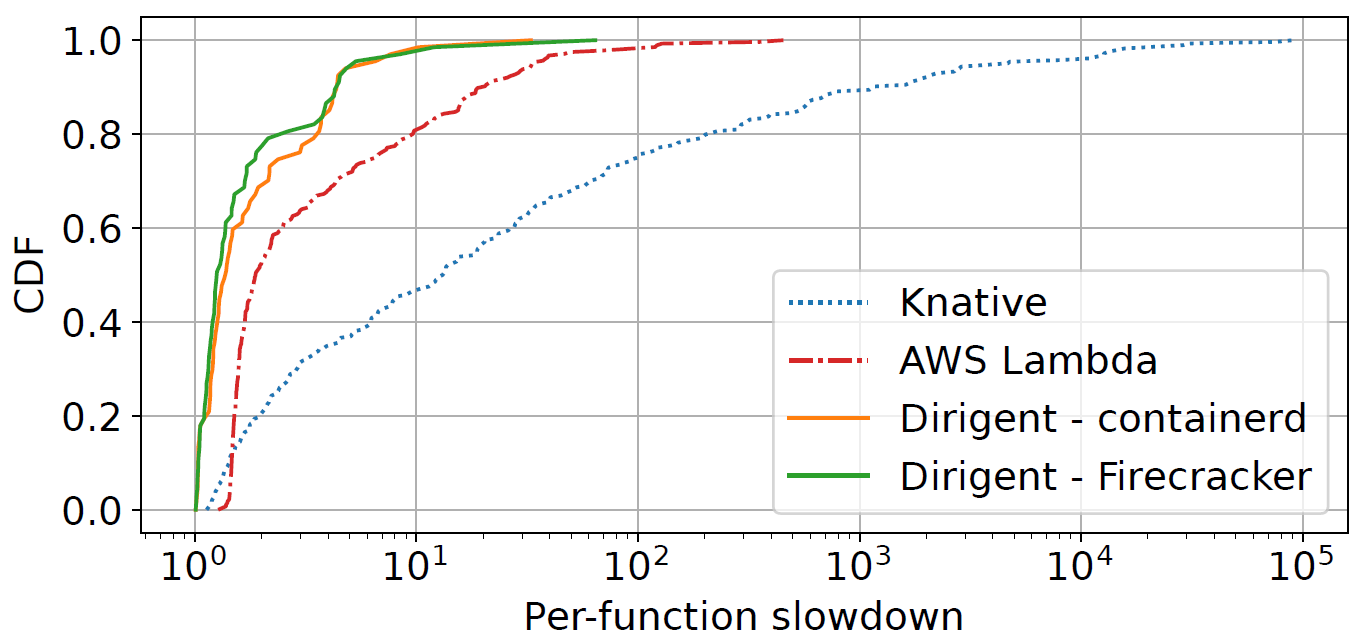
Conclusion
Dirigent is a new clean-slate cluster manager for serverless that aims to eliminate scheduling bottlenecks present in today’s platforms like Knative, OpenWhisk, and AWS Lambda. Dirigent is applicable for research in serverless and for orchestrating your own serverless cloud. More information and low-level details about the work can be found in our SOSP’24 paper. Dirigent is an open-source project and is available at external page https://github.com/eth-easl/dirigent/.